TTS and STT
There has been a rapid growth in AI‑enabled audio recording devices that convert speech to text and provide summaries. These devices often come as sleek, standalone units, shaped like a credit card or a small button, but they are costly.
- You need to buy the hardware (₹8,000–₹20,000).
- Their transcription services are limited by pay-walls.
- Subscription charges are high.
- They come with privacy issues.
This led me to explore various options for text-to-speech (TTS) and speech-to-text (STT) conversion that can run locally.
Speech-to-Text (STT)
Whisper by OpenAI has become a widely adopted standard for STT. It is fairly accurate for clearly spoken English and supports many languages, including Malayalam, although accuracy varies depending on pronunciation and audio clarity. After transcription, the text can be summarized locally using models run through Ollama.
EasyWhisper UI is a desktop interface built on top of the Whisper model, developed by the GitHub user mehtabmahir. It runs locally and performs reliably for general transcription tasks.
We can record the voice and the audio file can be dragged and dropped in to the UI, which generates a .txt file of the transcript in your computer, all done locally.
Text-to-Speech (TTS)
The TTS field is advancing even faster than STT, with many neural models trained on diverse datasets.
Models I tried:
- DIA 1.6B
- Coqui TTS
- Kokoro TTS
DIA TTS is large and requires around 100 GB of storage and at least 10 GB of GPU memory, which makes it impractical for most personal computers. So I ruled it out quickly.
Coqui TTS is based on the Mozilla TTS project, but in my experience, the interface and audio quality were not ideal.
Kokoro TTS
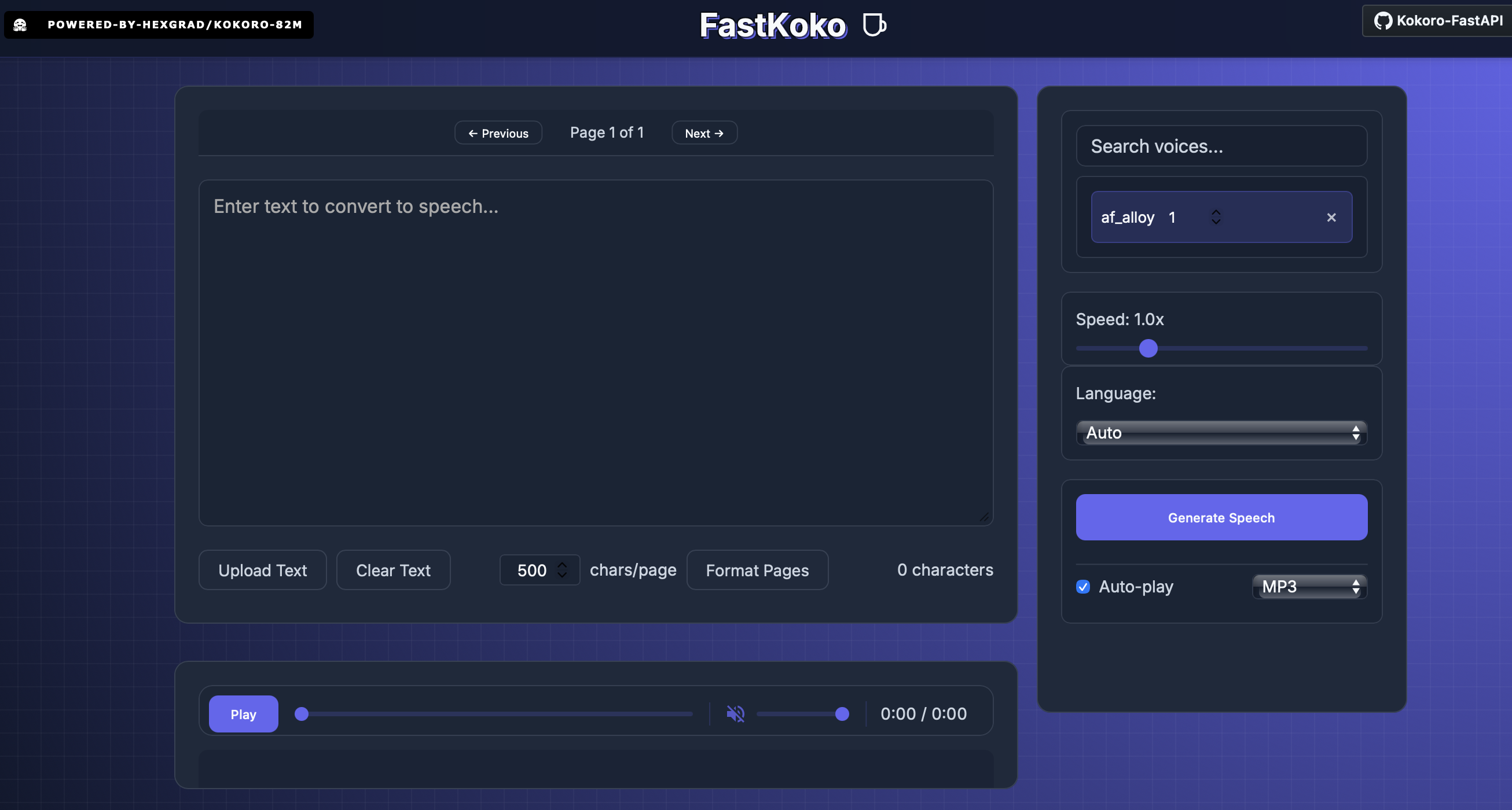
“Kokoro” in Japanese means heart, mind, and spirit as one—referring to the innermost essence of a person. The Kokoro TTS model is surprisingly lightweight (around 7–8 GB) and supports straightforward installation via Docker, which makes setup simple and clean.
Back to top